( ESNUG 570 Item 2 ) -------------------------------------------- [04/04/17]
Subject: Nvidia uses MENT Nitro physical floorplanning for ICC/ICC2
Seeing that the Mentor U2U'17 is happening this morning, plus the fact that
MENT Sierra/Oasys has made the news lately (ESNUG 568 #1) I figured out this
would be a great time to publish my Sierra/Oasys U2U notes from last year.
(Just under the deadline, I'd say!)
- http://www.deepchip.com/items/0570-01.html
From: [ John Cooley of DeepChip.com ]
The Nvidia group started out as an all-Cadence floorplanning house; old CDNS
Encounter EDI, not the Innovus stuff. This was user talk was about their
migrating floorplanning over to Nitro-SoC floorplanning -- they stayed in
ICC/ICC2 for PnR.
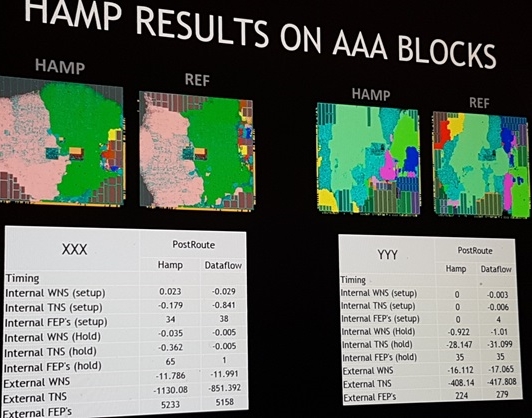
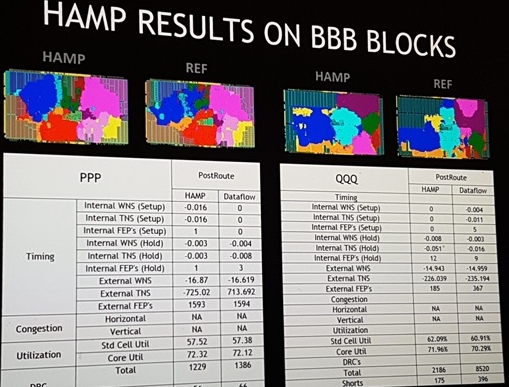
They compared Nitro floorplans to 8 different hand-floorplanned "Reference"
(REF) tapeouts. Ranged from 20 to 40 million inst, with most blocks around
1 million inst each. 16nm TSMC. Most are 1+ Gz designs.
1. feed Verilog gate netlists, grouping info, plus SDC into Nitro-SoC
2. Nitro runs timing-driven flat placement (flat DEF)
3. Nitro carves out partitions (blocks), (hierical DEF)
4. Nitro places the pins & feedthroughs (timing & congestion driven)
5. Nitro derives floorplan timing budgets
6. Nitro places all the macros in the floorplan
7. Write out hierarchical DEF/SDCs for each block for their
final ICC/ICC2 PnR
They used in this REF vs. Nitro floorplanning comparision:
- Nitro Hierarchical Automatic Macro placement (HAMP)
- Nitro block pinning and feedthrough insertion
- Nitro physical SDC generation for blocks
---- ---- ---- ---- ---- ---- ----
OVERVIEW:
The HAMP stands for "Hieraical Automatic Macro Placement". I got the sense
that HAMP might have been an Nvidia name, not a MENT name. Anyway, it's
used for both top-level and block-level of their designs. (Nivia designs
have 100s of macros. Manually placing all of them would crush their release
schedule.) The Nvidia guy said they ran the HAMP flow with multiple recipes
and compared QoR and runtime with their REF design.
Multiple recipes let them explore PPA options on their blocks.
What they fed Nitro for floorplanning were parameters like:
- % utilization
- aspect ratio
- macro-groupings
- BIST-connectivity
- Vt classes
- track sizes (8 to 12 tracks over cells)
- Mhz - Ghz
All of the Nitro automatic macro placement took 12 hours or less, and gave
"better or similar QoR" as compared to their matching REF floorplan.
It also gave Nvidia a 100% legalized floorplan to start in ICC/ICC2 PnR,
but I had the sense they weren't married to any PnR tool as long as it
could do 1 million to 2 million inst blocks quickly and legally.
Again, Nitro HAMP floorplanning runtimes were overnight (12 hours).
Notice the QoR metrics. Everything was either similar or better than hand
placed??? Then I remembered how hand floorplanning works. Your manager
holds a gun to you head and says "I need this floorplanned in 2 weeks!"
BBB blocks was not the Better Business Bureau - it's a anonymous block name.
He can't give out any real block names.
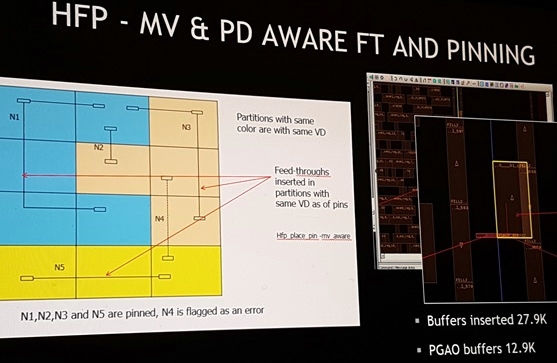
HFP means Hierarchical Floor Plan. Once you carve your blocks up based on
the flat placement (from step #4 above), you need to place the pins on the
boundaries of the blocks.
Nvidia is a beta customer for Mentor floorplanning -- they helped develop
its replicated its pinning -- hierarchy pinning, bus pinning, cluster
pinning, shield aware pinning, multivoltage-aware pinning, etc.
The Nvidia guy said that because Nitro does timing and congestion aware
pinning, it makes Nvidia ECO iterations go from 3 weeks to a few days.
He likes that the new Nitro makes incrementals "easy & fast", too.
Nvidia does abutted floorplans (not channel based at all) and feedthrough
insertion can get very complicated with all the replication, multi-voltage
requirements, busses, shields, etc.
HFP == Hierarchical floorplan
MV == Multi-voltage
PD == Power domain
FT == feedthrough
The background colors are the power domains the block lives in. There are
3 different power domains here (blue, yellow, and tan). N4 is an error
because it has a feedthough going between 2 different power domain.
Notice these are replicated blocks. So the pinning (assigning pins to the
boundries of the blocks) needs to be synchronized across all neighboring
blocks.
REF was originally ~8000 feedthroughs. Nitro floorplanning dropped it to
2343. That's a 70% drop. You never get zero feedthroughs, but less is
better. Makes for easier PnR.
The finale was the Nvidia guy yarping about how Nitro could generate
accurate block-level timing budgets. He was happy that Nitro was using a
physical SDC flow to do this. The whole chip is loaded up, and then after
routing, Nitro creates the interface timing budgets based on the real
interfaces. (Primetime just estimates this, often wrongly. Nitro-SoC
actually routes all of the interconnect signals and extracts them to get
accurate delays. Primetime doesn't do this because it only does timing.)
The other thing the Nvidia guy liked was Nitro-SoC has an across block
budgeter. Does proportional delay budgeting across each blocks while
maintaining the accuracy with the interface path routes. The quality of
budgeting impacts the PPA of the blocks and so it is important for Nvidia
to get the IO constraints right before feeding the blocks to ICC2 PnR.
WARNING: This was only a gate-level Nitro floorplanning talk, not a full
Nitro PnR eval. Nvidia spends most of their design time in floorplanning.
Once it gets to blocks, PnR is pretty much push button. Nvidia's secret
sauce is killer floorplanning. Block PnR is an afterthought for them as
long as their PnR tool can layout ~1 million inst blocks -- which ICC, ICC2,
Innovus, Nitro, and even the old Atoptech can do today.
- John Cooley
DeepChip.com Holliston, MA
---- ---- ---- ---- ---- ---- ----
Related Articles
How Samsung uses Oasys-RTL inside their IC Compiler II flow
Nvidia uses MENT Nitro physical floorplanning for ICC/ICC2
ST used Nitro-SoC for full PnR on ultra-low power IoT chips
Join
Index
Next->Item
|
|