( ESNUG 586 Item 6 ) ---------------------------------------------- [04/23/19]
Subject: Chi-Ping Hsu answers the 6 big technical doubts about Avatar PnR
Since, I have no idea who'll be at the Avatar booth at the TSMC OIP event
today, I have a fun set of questions to ask 4 different key guys who may
or may not be there.

Chi-Ping Hsu
Avatar Director
|

Ping San Tzeng
Avatar CTO
|

Charlie Huang
Avatar Director
|

Suk Lee
TSMC Director
|
My 6 Cooley questions to ask Chi-Ping Hsu and Ping San Tzeng ...
- Avatar rumors plus 6 core questions to ask at TSMC OIP
From: [Chi-Ping Hsu of Avatar]
Hi, John,
I saw the 6 doubtful questions you posted the very morning of the TSMC OIP
in Santa Clara on 10/03/2018. (And I want to give you a big "thanks" for
the timing of that.)
Could you do me a favor and at least post my answers to your questions by
the 2019 TSMC Technology Symposium on 04/23/2019, please?
- Chi-Ping Hsu
Avatar Integrated Systems Santa Clara, CA
---- ---- ---- ---- ---- ---- ----
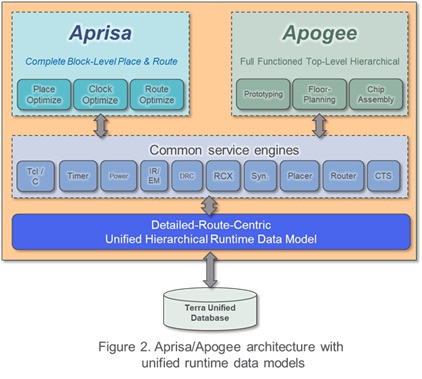
1.) What's this about your claims that the Avatar data model and
Avatar database are more unified than Innovus / ICC2 databases
and data models?
In our terminology, the "database" is the design data storage in the hard
disk. The "data model" is the runtime design data in RAM.
While a unified database is important to a PnR tool, Avatar's in-memory
unified data model is the critical technology that enables us to do our
Detailed-Route-Centric P&R.
Aprisa/Apogee has the industry's only in-memory unified PnR runtime data
model. For traditional P&R systems (like Innovus and IC Compiler II) as
shown below, the placer, router, timer, rcx, or other PnR engines may
create its own runtime data model to perform its function. Since their
data models are distinct and dedicated only to each engine -- passing
data or attributes between those different engines is inefficient and
often leads to inconsistency.
Frequently, with our rival's PnR, one engine would need to pack and save
data into files, before the other engine can read and re-construct the data.
With so many engines in a modern PnR system, communications between engines
are far too inefficient to perform -- and the system tends to be unstable
and difficult to maintain.
On the other hand, with our Aprisa/Apogee's in-memory unified runtime data
model, below, all our PnR engines access to the same design objects in
memory. The benefits of this revolutionary approach are:
- Sharing and passing attributes/data between engines is as simple
as just marking and updating to the design objects directly.
- Each engine has access to full design attributes/data at all time.
- Each engine can invoke other engines incrementally and interleavingly.
- Full design attributes/data is accessible by third party applications
through Tcl/C API.
This is critical for sub-16nm designs where detail physical information is
required for accurate and consistent analysis. For example, the shape of
a wire and its corresponding RC are required for accurate EM analysis.
Since this info is readily available in our unified data model, our EM
analysis engine has the full visibility of the physical wires at all time,
and our EM analysis can be invoked by other Avatar PnR engines at every
step throughout our flow.
In contrast, without the unified data model, PnR engines must export shape
data through DEF, and RC data through SPEF, to the (sometimes 3rd party)
EM engine -- and hence the link between each physical shapes and its RC
electrical information would have been lost.
In addition, detailed routing with our precise RC, timing, and congestion
estimation can be updated by our router for our placer periodically and
incrementally with our unified data model.
This makes the Detailed-Route-Centric P&R technology possible.
The Avatar R&D team that created this innovative architecture has received
"Design Team of the Year" award at ARM TechCon 2018.
2.) The standard everyday PnR flow goes in 8 basic stages
1. placement
2. trial route
3. post-placement optimization
4. clock tree
5. post-clock tree optimation
6. global route
7. detailed route
8. chip assembly
INSTEAD your detailed-route-centric approach is supposed to
run at every point in the 7 stages??? WTF? How does this
even work???
With our Detailed-Route-Centric P&R, our PnR design flow remains similar.
The main new capability is that during placement, post-place optimization,
CTS, and post-CTS optimization -- we can afford to call the router more
frequently than traditional approach -- and provide the exact and consistent
detailed routing condition for each signal.
It's because of our unified runtime data model architecture. At sub-16nm,
where resistance dominates timing and EM -- precise and consistent detailed-
route estimation (such as routing layers, vias, pin connection, and routing
patterns) is critical to the quality of designs at those earlier stages of
PnR.
With the precise detailed route estimation for critical signals readily
available, our Avatar timing and IR/EM calculation used to perform those
steps (such as post-place optimization) is more realistic. In addition,
our detailed-route estimates would be available to our router at the final
detailed-route stage to make sure our routing results are consistent to
those earlier Avatar estimates.
With our internal consistency:
- count of Avatar PnR iterations is greatly reduced,
- optimization can be done more predictably and efficiently, and
- your overall design closure time is shortened, and
- the design timing, power, and area are improved.
In one example, a customer took 3 months iterating and tuning all the nobs
in their (it shall remain "unnamed") PnR flow on a 16nm design, just to get
some acceptable QoR. But, with Aprisa, they got better QoR in 2 weeks;
using almost only out-of-box settings!
With our approach, design closure is easier and more predictable, and it
gets better QoR.
3. you put out marketing hype on Path Based Timing analysis;
isn't this like what CLK-DA did -- and won't it consume too
much compute time to be viable?
It is true that directly applying PBA (Path-Based Analysis) on all paths and
at every step during any PnR flow would cause impractical and unnecessary
computation overhead.
Our Aprisa automatically combines PBA with GBA and our patented statistical
optimizations over the entire PnR flow to deliver close-to-signoff PBA
correlation and better final PPA at affordable computational cost.
For example, on a 16nm design with 4M instances, PBA got:
WNS TNS Leakage Runtime
----- ------ ------- --------
P&R w/o PBA -153p -62.3n 476.3 ~100 hrs
P&R with PBA -90p -5.8n 323.4 ~105 hrs
Note: with only 5% more runtime, our PBA gets substantially better timing
and more than 30% better power. On the other hand, if brute-forced PBA
is used during PnR, the total runtime would have easily been exponential.
4.) Why aren't there any *certified* TSMC 7nm tech files out yet
for the Avatar Aprisa/Apogee PnR tools?
Yes, Avatar has been certified by TSMC for 7FF, and all 7FF P&R techfiles
are now available for immediate design starts.
We have been collaborating with TSMC on 7FF certification since 2016
(ATopTech), and we completed (signed-off by TSMC) all 7nm certification
projects from 7FF DRM v0.1 to v1.0.
As a matter of fact, ATopTech received TSMC "2016 Partner of the Year for
7nm Mobile Design Platform" award at TSMC OIP, Oct. 2016.
Since Q4 2018, Avatar has worked with TSMC to "re-certify" Aprisa/Apogee
for the latest 7FF technology (DRM v1.2). The certification process is
now completed and official marketing announcement will be out shortly.
In the meantime, there are multiple key customers using Aprisa on 7FF
production projects. Up-to-date Aprisa 7FF techfiles are available upon
request to start any 7FF projects.
5.) Is Avatar in trouble because it doesm't have native access to
Primetime and Tempus for *basic* STA stuff? How do you do
final signoff *without* Synopsys PT or Cadence Tempus?
Yes, Avatar does not have access to standard alone signoff STA, such as
Primetime or Tempus. However, Avatar R&D has expertise in signoff STA
and created complete signoff quality STA within our P&R based on our
unified runtime data model. Aprisa's built-in STA enjoys a reputation
of excellent correlation against signoff STA. (This is because STA
fundamentally is based on physics. If every STA tool does their analysis
strictly based on physics, their final numbers should be the same or very
similar to ours.) Avatar R&D made our full timing analysis engines without
shortcuts, thus its results are very reliable and accurate as any reputable
signoff STA tools.
And since our built-in STA has excellent correlation with standalone
signoff STA, it significantly cuts the number of timing ECO iterations.
Note that all our customers has access to Primetime or Tempus, and they all
constantly measure our timing against the signoff STAs. And they have been
very happy with our STA correlation.
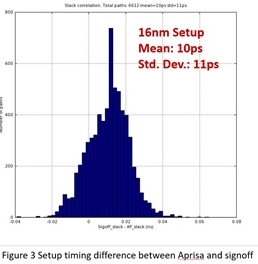
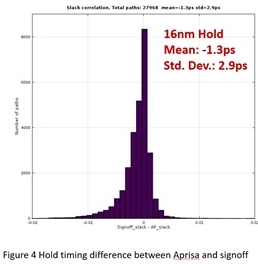
The above histograms show the setup and hold timing differences between
Aprisa and signoff STA. Both figures are from customer 16nm designs with
all the advanced timing features, including PBA, waveform analysis, low
voltage, CCS for delay and SI analysis. Note the tight correlation of
Aprisa timing with signoff STA -- with very small mean and std deviation
for both setup and hold time.
6.) On SI and crosstalk issues, Avatar has zero access to Cadence
Celtic, Apache RedHawk, nor Synopsys PT-SI -- won't your
beloved Aprisa REV2 suffer from a "Gargage In, Garbage Out"
problem with 7/5nm delay calculations?
This question is similar to question 5 above. Our Aprisa does complete
signoff quality IR/EM/SI analysis based on physics and does not take
"short-cuts" when calculating these effects.
In addition, with our analysis running on our unified runtime data model,
many SI related effects that most rival PnR tools ignore are taken into
account natively. As a result, our Aprisa timing get great correlation
against signoff STA/SI. Similarly, for the correlation against RedHawk.
Also, at sub-16nm, accurate (and consistent) IR/EM/STA/SI analyses rely
on the availability of precise and timely detailed route data throughout
your entire P&R flow.
If the inputs to your IR/EM/STA/SI engines are not consistent to the
final routing results, they may encounter "Garbage In Garbage Out" problem,
and their analysis results may not be trustworthy.
With our Detailed-Route-Centric P&R technology, the inputs to all of our
analysis engines are always close to the final routing -- and, therefore,
the outputs of the analyses are more consistent throughout the flow.
This consistency reduces the number of P&R iterations, and shortens the
time for design closure.
- Chi-Ping Hsu
Avatar Integrated Systems Santa Clara, CA
---- ---- ---- ---- ---- ---- ----
Related Articles
Avatar/AtopTech's big comeback in digital PnR is #4a "Best of 2018"
SCOOP -- Avatar rumors plus 6 core questions to ask at TSMC OIP
Synopsys layoffs means ICC2 rewrite is unknown for 3 to 4 years out
ICC2 patch rev, Innovus penetration, and the 10nm layout problem
Join
Index
Next->Item
|
|