( ESNUG 582 Item 8 ) ---------------------------------------------- [05/11/18]
Subject: Shiv on IC Manage PeerCache for cloud bursting without EDA retooling
SCOOP! -- In his CDNlive keynote, CDNS SVP Tom Beckley accidentally
Leaked on stage that for its customers Cadence is moving its Verilog
simulation tools into the Amazon AWS cloud. "You'll see more at DAC!"
Clearly this announcement wasn't planned because his staff looked
very unhappy when I asked for details about this. (Oops.) - John
P.S. now the question is: "what are Synopsys and Mentor going to do?"
- John Cooley of DeepChip.com (05/02/2018)
From: [ Shiv Sikand of IC Manage ]
Hi, John,
Nice scoop, and a great move by Cadence. We're seeing the IC design and
verification teams virtually across the board frustrated with wasting
time waiting to access their LSF compute farms. They want to be able to
instantly run 500 licenses on their job *now* -- not queue it up and wait
for their turn.
We see a BIG demand right now in the chip design/verification world for
*true* instant "elastic compute"; especially for compute intensive runs on:
- Cadence Incisive, Synopsys VCS, Mentor Questa
- Synopsys Primetime, Cadence Tempus
- Mentor Calibre DRC/LVS
- Ansys RedHawk, Cadence Voltus
... plus all the different SPICE simulators and other tools used for library
characterization runs.
My company, IC Manage, is working on a number of chip design & verification
pilot projects where our customers extend their existing on-premise EDA
compute power by 'bursting' into the cloud for (pretty much) unlimited
high-performance compute resources.
For many years, cloud use stalled in chip design due to security concerns.
But now in 2018, chip design companies -- wooed by both "on-demand" compute
power and the promise of pay-only-for-what-you-use SaaS pricing -- have
been doing aggressive security due diligence on the Amazon, Google, and
Microsoft clouds.
And these cloud vendors are now passing security muster.
---- ---- ---- ---- ---- ---- ----
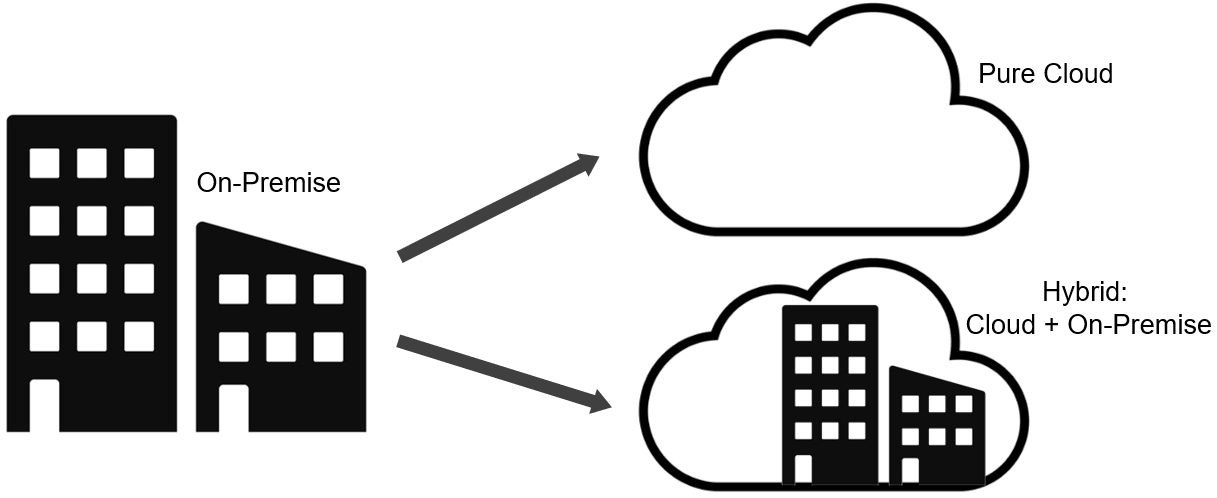
THE TWO WAYS OF CLOUD FOR CHIP DESIGN
Although the true market breakout is complicated, here are two general ways
that the big & small system, IoT, AI, and semiconductor houses are adopting
cloud for chip design and verification:
1. A "Pure Cloud" Design Flow
These are the EDA and chip design workflows custom built to run
only in the cloud. These are NOT EDA tools adapted to the cloud;
architected to take advantage of the parallelism and storage
differences of the cloud.
A pure cloud toolset appeals to start-ups and smaller customers
like IoT, automotive, and AI chip companies who are interested
in elastic compute runs and they don't already have an entire
chip design workflow environment built from scratch.
Also interested are some of the mid-sized chip design companies
wanting to move away from having to manage their own data centers;
and instead want to outsource their LSF compute farms to pure cloud.
2. A Hybrid "On-Premise-Plus-Cloud" Design Flow
These "hybrid" workflows combine the cloud with older existing
on-premise LSF compute farms. These on-premise users want to
scale to 'cloud bursting' during peak EDA demand.
They have 10's to 100's of millions of dollars and man-hours
invested in on-premise workflows and EDA tools and scripts and
methodologies and compute farms that they *know* work *now*.
They're not going to throw away WHAT WORKS just for WHAT'S NEW.
Those moving to a hybrid cloud are likely to start with a limited cloud
footprint, and then ramp up their cloud portion over time. This minimizes
risk and while cutting the total costs associated with maintaining secure
on-premise LSF compute farms.
I will focus the rest of this discussion on hybrid workflows, as they are
likely to be the most common for the next few years.
---- ---- ---- ---- ---- ---- ----
THE GOTCHAS OF HYBRID CLOUD WORKFLOWS
The big chip design workflows are typically mega-connected NFS environments,
comprised of 10's of millions of files, easily spanning 100 terabytes:
- EDA vendor tool binaries - with years of installed trees
- 100s of foundry PDKs, 3rd party IP, and legacy reference data
- Massive chip design databases containing timing, extracted
parasitics, fill, etc.
- A sea of set-up and run scripts to tie all the data together
- A nest of configuration files to define the correct environment
for each project.
These 10's of millions of horrifically intertwined on-premise files
makes for one very Big Gotcha for those trying to move to the cloud.
And that is: On-Premise workflows are not the same as Cloud workflows.
The details of this Big Gotcha breaks out to 7 parts:
1. Uploading your first design to the Cloud takes weeks to months.
In the cloud, block storage is the norm, while on-premise EDA
tools are built on NFS-based shared storage.
Why it matters:
- Block (cloud) storage is typically only accessed by one host at
a time, while (on-premise) EDA workflows have lots of shared
compute nodes that expect to see the same coherent data across
millions of nodes.
This is common in high-performance computing applications. The
large parallel on-premise file systems like Glustre, GPFS, Ceph
were NOT written for chip design datasets.
- This on-premise data coherency across many compute nodes is done
by an on-premise NFS Filer like NetApp or Isilon -- but no such
equivalent function is available as a native instance in the cloud.
- Amazon does offer a shared storage solution called EFS (in contrast
to the other cloud vendors). However, while EFS can scale to many
millions of nodes, the single node performance of EFS is much lower
than what an on-premise high-performance shared filer can deliver.
So, the way companies have tried to replicate and run their existing
on-premise workflows into the cloud has been to:
Step #1. Set up the cloud tool environment
Step #2. Copy your on-premise data into the cloud
Step #3. Configure and run in the cloud
Step #4. go back to Step #2
Figuring out the correct subset of on-premise data and copying it into
the cloud is not easy. It's time consuming because it is extremely
hard to know all the interdependencies. Moving to the cloud breaks
because the right on-premise data set was not copied into the cloud
correctly and incremental updates are painfully slow. So, you try
again and again -- Lather, Rinse, Repeat.
I've seen this loop of taking your on-premise design into the cloud
take 3 weeks to close -- just for one block running VCS at one
process node. I know of other cases where it took 3 months.
2. Design changes take time to upload into the Cloud.
It's actually FREE to upload design data into the cloud. However, as
you work on your chip making small changes, tweaking and adjusting,
updating your PDKs, etc. -- you have to rsync all these design
deltas into the cloud. And rsync can take hours to a day...
creating a time-consuming (and thus expensive) upload latency where
you effectively lose the fast compute benefits of cloud bursting.
3. Downloading data from the Cloud is *never* free.
While uploading is free, downloading costs. All of the cloud vendors
make you pay to transfer your data from the cloud back on-premise.
It can quickly add up to $10/GB, making a 5 TB design cost $50,000
if you're silly enough to try to download it. (Instead you only
download small 5 MB run reports on it; *never* the whole design.)
The caveat here is to have tight control on your cloud return paths.
4. You must always have TWO copies of your design at all times
Most work/changes/tweaks/ECOs/fixes/repairs done on your design are
typically done on-premise. And after each delta you then upload
that new rev into the cloud. This means you must constantly
synchronize your on-premise dataset with each additional cloud
projection. This synchronization can be error prone -- similar
to the sync problems multi-site developement teams see.
5. Compute and storage costs are cheap, but it adds up quickly.
In the Nor Cal Zone, Amazon EFS storage pricing $0.33 per GB/month,
so to store 100 GB of data for a month will cost you $33.00 -- which
doesn't seem like much until you realize a full enviroment can be
5 TB, or $1,650 a month to store. For AWS compute costs:
US West (Nor Cal)
m4.2xlarge 8 vCPU 32GB $0.40 per Hour
m4.16xlarge 64 vCPU 256GB $3.20 per Hour
which seems very affordable until you spawn off 1000 nodes to run
for a week and (1000/64) X $3.20 X 24 X 7 == $16,275. It adds up.
6. Scale out to the Cloud is hard.
Building your own NFS solution in the Cloud using standard Linux
servers only really works for mid- to low-end performance. Filers
and Linux based NFS servers are "scale-up" (a bigger box) solutions,
while cloud architectures are built for "scale-out" (add more boxes).
If you are a small company, you can roll your own NFS and copy the
data into the cloud. However, if you are a larger company, the
cost of doing this can be extremely high and leads to paying for
storage multiple times.
7. Delete when you're done to prevent future data leaks.
If it doesn't need to be up there in the cloud for extended periods
of time, be sure to delete it. It's simply the law of entropy. Just
like national parks: "take only memories, leave only footprints."
The bottom line is that IC design teams have been struggling trying to get
cloud bursting for their data heavy, shared storage chip design workflows.
And the EDA vendors who want to meet customer demand for cloud tools face
a steep ramp-up trying to build new EDA workflows that take advantage of
cloud parallelism.
Which leads me to IC Manage's big news today.
---- ---- ---- ---- ---- ---- ----
IC MANAGE PEERCACHE: ON-DEMAND HYBRID CLOUD BURSTING
This is my third year discussing PeerCache in DeepChip (2017, 2016).
Our prior version of PeerCache cuts the overall NFS disk storage you need
and does performance/scale-out for on-premise environments. I'm proud to
announce:
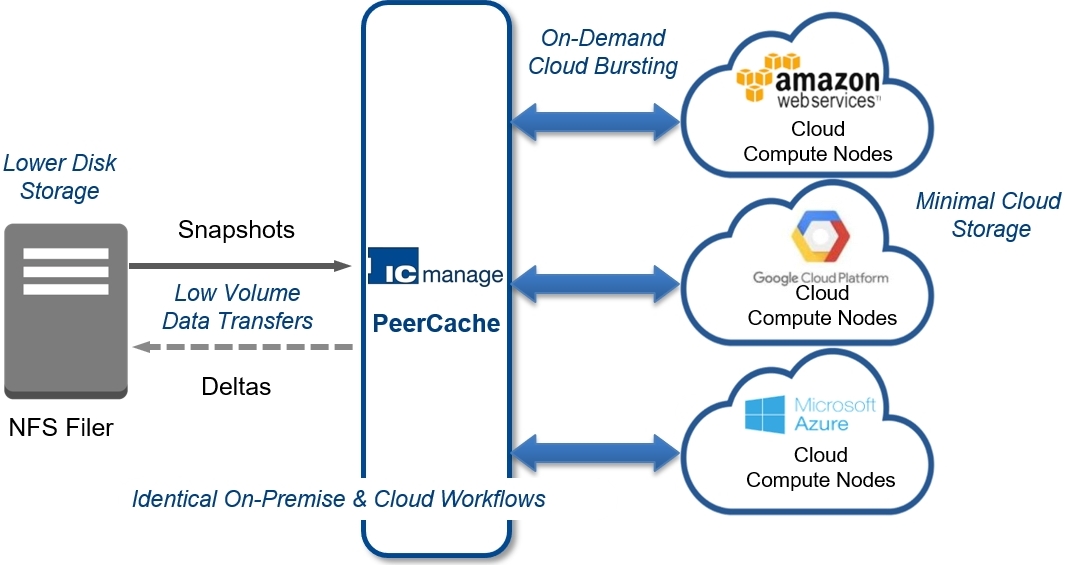
1. PeerCache now provides hybrid cloud bursting. You can now run your
existing on-premise EDA workflows in the cloud without any changes.
2. It delivers elastic, high performance scale-out with minimum data
transfer for low-latency uploads and cost-optimized downloads.
And since we know that hybrid cloud bursting and elastic computing is what
customers want now, the rest of my article will be on how PeerCache works.
PeerCache hybrid cloud bursting means the EDA end user sees the same compute
grid as is on his/her on-premise queues.
1. Workflows run the same On-Premise, or in the Cloud, with no retooling.
PeerCache automatically and dynamically determines the exact workflow
data (tools, environment & design data) needed by a job. It's able to
do this because of the fundamental architecture we've pioneered -- we
separate metadata from data. (See ESNUG 561 #2.)
2. Absolute minimum in/out Cloud data transfer for low latency bursting.
PeerCache does ultra-fine granularity data transfers. It understands
file extents. If you "read" only a few bytes of a large file and then
append to that file, PeerCache is unique in that
- Only bytes that are "read" are forward transferred into the
cloud,
and
- Only the extent deltas that are written are transferred
back to the on-premise NFS filers.
When engineers make copies of PeerCache datasets, they no longer use
the cp or rsync commands. Instead, they simply ask PeerCache to
*clone* the data, which generates *virtual* copies. This let's them
create fully isolated independent work areas of massive data sets,
but only use *incremental* storage space for asynchronous write-backs
to your on-premise storage. PeerCache saves only the delta changes
back to your NFS -- it never copies duplicate data.
For example, if you create any number of parallel workspaces, the
modified files are tracked as deltas of the original. The transfer
back to the on-premise storage is minimized, and the deltas can then
be expanded into discrete files as directed by your database.
PeerCache also allows selective writeback control to prevent users
from accidentally or unwittingly pushing unnecessary data back
across the wires.
Since getting your data back from the cloud to on-premise is typically
expensive, by only downloading deltas it cuts your data download fees.
3. Now you do NOT need TWO copies of your design at all times.
These shared peer caches eliminate the need for duplicate storage
because the copies are now in the cache fabric -- and not in your cloud
storage or in your on-premise storage -- which cuts both your cloud
and on-premise storage costs.
BTW this feature also allows you to decouple your on-premise compute
nodes from your existing NFS filer storage bottlenecks. As discussed
in ESNUG 571 #5 PeerCache already reduces your NFS filer storage.
4. This is true on-demand hybrid cloud bursting.
Using PeerCache your Amazon/Google/Azure cloud works transparently.
That is, your EDA jobs can now be scheduled in the same way as you did
on your local on-premise queues in your LSF compute farm grid.
You can do your overnight regressions in the cloud, or on-premise, with
no additional effort. It's transparent to the end user.
5. Your data disappears when you are done cloud bursting.
PeerCache cloud bursting uses only temporary cache storage. So the
moment you shut down the peer instance, there is no data left stored
in the cloud. You would shut down the trackers, too, but that's
a detail. The point is when you are done your data disappears
leaving no trace -- eliminating any potential leakage risk.
6. Low cost and hassle-free scale-out.
You simply run additional PeerCache peer nodes as part of your cloud
auto-scale groups. This ensures consistent low latency and high
bandwidth parallel performance at all times -- eliminating traditional
storage bottlenecks.
I will discuss this in detail in a later section on "scale-out".
---- ---- ---- ---- ---- ---- ----
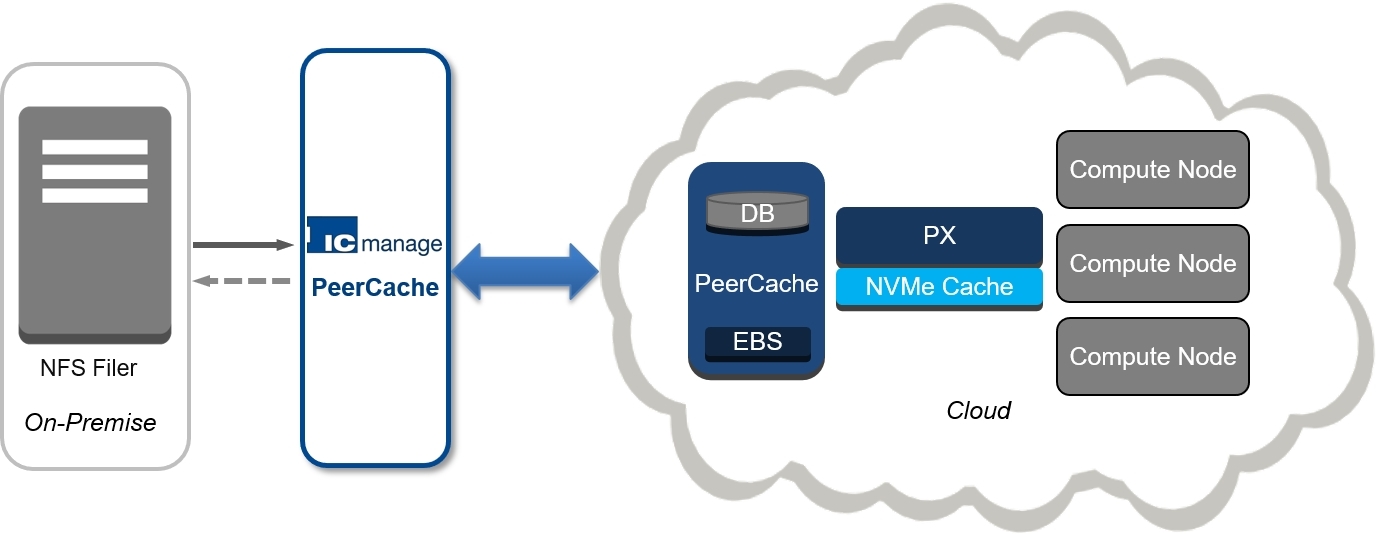
ONLY MINUTES TO HYBRID CLOUD BURSTING
The entire PeerCache set-up process to extend your existing infrastructure
into the cloud (and/or to remote sites), takes only a few minutes. There
are 3 short steps:
1. [YOUR ENGINEER DOES] Identifies your NFS filer mount points and
namespaces via a series of filer snapshots, and then passes the
information to PeerCache at your on-premise location. (This time
will vary slightly depending on how much metadata indexing you
need to do).
2. [PEERCACHE DOES] Replicates your on-premise filer mount points and
creates a virtual representation on a remote compute node, using
only a bare operating system of your choice.
3. [PEERCACHE DOES] As your EDA jobs run, it transfers the file extent
data into the remote PeerCache database and caches it locally to
the peer nodes.
THAT'S IT! YOU'RE DONE! Once the cache requests have been fulfilled, no
further data transfers are required between on-premise and cloud -- your
cloud or remote site is fully decoupled from your on-premise environment.
You do not need to run special tools nor use special EDA environments that
run natively in the cloud. Your existing EDA workflows are preserved and
work precisely the same in the cloud as they did on-premise.
PeerCache avoids lengthy post OS configuration; it brings up a "naked"
cluster when you run a job from scratch -- all it needs is the right OS and
security configuration. You avoid the full, lengthy software provisioning
procedure since the binaries and data for the job are treated identically
and delivered at file extent granularity.
PeerCache also enables fast tear down of your environment, only requiring
one database on a single node with locally connected block storage to serve
as a warm cache for subsequent bursting operations.
PeerCache is both cloud and EDA vendor agnostic. PeerCache supports a mixed
EDA vendor environment. You can have that same Cadence + Synopsys + Mentor
+ Real Intent + whatever other point EDA tools you had in your on-premise
flow now in the cloud -- without having to change a thing! Plus, you get
to pick your cloud vendor. (We don't pick anything for you.)
In addition to design and verification teams, EDA vendors themselves can
also use PeerCache to quickly meet customer demand for cloud tools without
the overhead of building a new workflow or new software architecture.
---- ---- ---- ---- ---- ---- ----
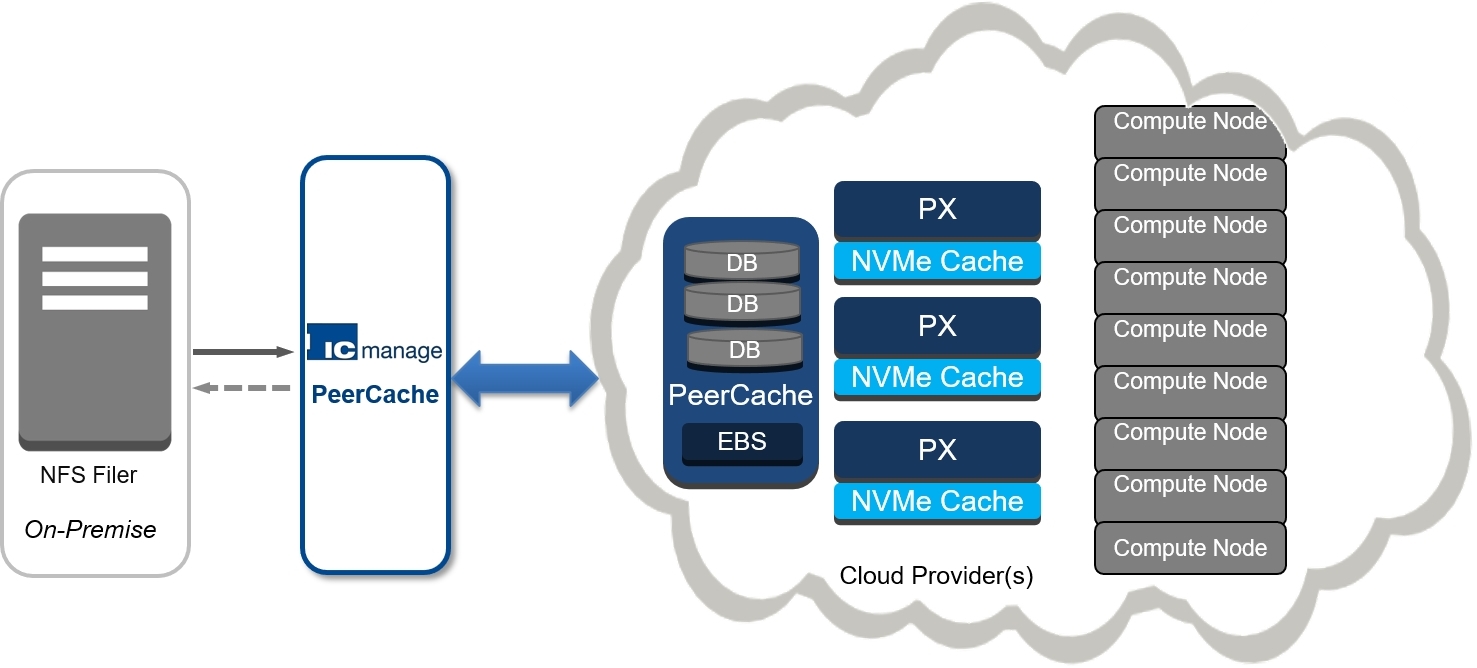
SCALE OUT FAST OR GRADUALLY ON THE HYBRID CLOUD
The way how PeerCache gives the user high-performance computing is by using
a peer-to-peer cache fabric that scales out by just adding more peers. This
was true even two years ago. (See ESNUG 561 #2) However, with these new
cloud bursting capabilities, many chip development teams only want to dip
their toe into cloud bursting at first and then gradually ramp up from there.
So PeerCache's architecture let's them scale-out as fast or gradually as
they want. It consists of one or more databases that can be provisioned
on block storage; the peer nodes use only small amounts of temporary
("ephemeral") storage using high performance NVMe devices (like the widely
available AWS i3 instance types.)
PeerCache's peer-to-peer sharing model allows any node to read or write data
generated on any other node. (Because this sharing model has the same
semantics as NFS, it's 100% compatible with all your existing EDA workflows.)
PeerCache lets you start with small hybrid
cloud bursting pilot projects
PeerCache behaves like an NFS filer -- with the same high resiliency -- but
with full horizontal scaling. It runs RAFT distributed consensus between
databases, so that if one unit fails, data coherency is still maintained.
And after the pilot, you can expand to 100s of thousands of nodes
The scale out architecture allows additional peers to be added in the cloud
or at your remote site into your infrastructure, giving you a fully elastic
cache fabric to go with your elastic compute.
Development teams can incrementally move select workloads into the cloud,
and then horizontally scale out as they evolve. Because it is file based,
PeerCache works with all SW applications in any domain.
---- ---- ---- ---- ---- ---- ----
ELASTIC COMPUTE FOR CHIP DESIGN IS HERE
After years of minimal movement, our industry is finally at a tipping point
with the cloud. Its adoption is being driven by development groups that:
- need cloud bursting during peak EDA tool use demand, or
- they want to add cloud-based workflows for their remote sites, or
- they just don't want to run their own data centers any more, or
- they want to spool up new projects without the 6 to 9 month server
capacity planning cycle.
Their CAD and development teams will drive the pay-by-minute (or by-second)
licensing models, third party IP access, and foundry permissions. The
customers and EDA vendors who adapt quickly will benefit the most. Those
who don't will be left behind.
Just check out the Infrastructure Alley at DAC this year. We now have both
Amazon AWS and Google Cloud as new entries in our chip design world.
- Shiv Sikand
IC Manage Campbell, CA
---- ---- ---- ---- ---- ---- ----

|
Shiv Sikand is Founder and EVP at IC Manage in Campbell, CA. Next year he will be racing against the clock in the 36 day,
~13,000 km 2019 endurance motor rally from Peking to Paris in his vintage 1969 Peugeot 504.
|
Related Articles
Shiv on 10x EDA I/O speed-up with IC Manage PeerCache P2P caching
IC Manage & Cliosoft get #5 Best 2017; MethodICs & Dassault missing
Shiv on ICM's PeerCache secure BitTorrent-style workspace tool
524 engineer survey says network bottlenecks slow EDA tools 30%
Join
Index
Next->Item
|
|