( ESNUG 541 Item 2 ) -------------------------------------------- [05/23/14]
Subject: Dean Drako warns "Big Data" analytics coming for chip design DM
> If I had to characterize this year's 2014 main report finding, it is
> that design and IP management has gone well beyond only one system at
> one site. In fact 82% of companies now have multiple design sites, and
> more than half of companies have at least 2 different DM systems.
>
> This complexity and duplication result in increasing interdependencies
> between teams. For the entire system to work, companies will need to:
>
> Have a global design view, while making
> local AND remote sites EQUALLY efficient
>
> The winning hardware design teams will use a combination of management
> policies/processes -- plus DM tools that have a global system view and
> IP reuse -- plus an adequate supporting infrastructure for every site;
> plus mechanisms to manage the all of the interdependencies.
>
> - from http://www.deepchip.com/items/0539-02.html
From: [ Dean Drako of IC Manage ]
Hi John,
I'd like to expand further on the 2014 DM post that I started a few weeks
ago in ESNUG 539 by discussing "Big Data" analytics and chip design.
The entire world -- both chip design and the real world -- is experiencing an
explosion in data volume. Roughly 90% of the data around today was created
within the last 2 years.
One promise of "Big Data" is to let companies instantly harness this growing
volume of data and apply analytics for the best possible business decisions.
   Big Data analytics are already being used in oil and gas, biomedical, video
recording, crime analysis, traffic management, consumer buying patterns,
travel, DNA sequencing, and finance.
Yes, Big Data is a big buzzword. It's used to describe emerging techniques
for:
- Capturing massive data volumes
- Accessing the data
- Extracting and sharing the data
- Analyzing and visualization data
A recent Bain study showed companies that use Big Data analytics best are:
- 2X more likely to have top-quartile performance
- 5X more likely to make decisions much faster than competition
Big Data is so prevalent that it has even reached bus stop advertising!
Recently I saw an ad on a bus stop that said: "We are all Data Nerds."
Two natural questions are:
"Can we use Big Data technology in chip design?"
"What competitive advantage will it give my company?"
---- ---- ---- ---- ---- ---- ----
POTENTIAL BIG DATA USES IN CHIP DESIGN
Building chips and SoC's creates data -- enormous amounts of data. Easily
one tapeout involves Terabytes of data. Contained in all this data are
potential insights that can change not only your final product, but also
the way design and project decisions were made -- in the race to get great
designs made in a compressed schedule and on budget.
Big Data analytics are already being used in oil and gas, biomedical, video
recording, crime analysis, traffic management, consumer buying patterns,
travel, DNA sequencing, and finance.
Yes, Big Data is a big buzzword. It's used to describe emerging techniques
for:
- Capturing massive data volumes
- Accessing the data
- Extracting and sharing the data
- Analyzing and visualization data
A recent Bain study showed companies that use Big Data analytics best are:
- 2X more likely to have top-quartile performance
- 5X more likely to make decisions much faster than competition
Big Data is so prevalent that it has even reached bus stop advertising!
Recently I saw an ad on a bus stop that said: "We are all Data Nerds."
Two natural questions are:
"Can we use Big Data technology in chip design?"
"What competitive advantage will it give my company?"
---- ---- ---- ---- ---- ---- ----
POTENTIAL BIG DATA USES IN CHIP DESIGN
Building chips and SoC's creates data -- enormous amounts of data. Easily
one tapeout involves Terabytes of data. Contained in all this data are
potential insights that can change not only your final product, but also
the way design and project decisions were made -- in the race to get great
designs made in a compressed schedule and on budget.
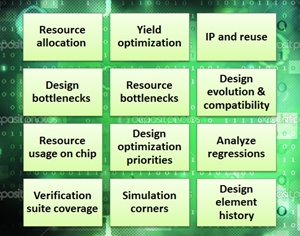 16 potential Big Data analytics uses in chip design
The 16 examples above are where "Big Data" analytics can make a real impact,
leading to better design and business decisions.
---- ---- ---- ---- ---- ---- ----
CHIP DESIGN BIG DATA: VOLUME, VARIETY, VELOCITY, & COMPLEXITY
Often big data is discussed as three areas: volume, variety, and velocity.
For IC design, I will add the fourth dimension: complexity, because it's a
major aspect of chip design.
---- ---- ---- ---- ---- ---- ----
VOLUME
16 potential Big Data analytics uses in chip design
The 16 examples above are where "Big Data" analytics can make a real impact,
leading to better design and business decisions.
---- ---- ---- ---- ---- ---- ----
CHIP DESIGN BIG DATA: VOLUME, VARIETY, VELOCITY, & COMPLEXITY
Often big data is discussed as three areas: volume, variety, and velocity.
For IC design, I will add the fourth dimension: complexity, because it's a
major aspect of chip design.
---- ---- ---- ---- ---- ---- ----
VOLUME
 Comparing SoC design data volume to other Big Data applications:
- Oil/Gas, Biomedical, etc.: 100's of Terabytes to 10's of Petabytes
- SOC/IC/IP design: 10's to 100's of Terabytes
SoC data volume is driven by: advanced process nodes, timing, 3D, layout,
power, characterization, modeling, synthesis, manufacturability, yield,
verification (simulation, regressions, physical verification...)
- Data volume is only getting bigger with smaller feature sizes,
due to nonlinear behavior at these nodes, as well as the physical
effects of decreasing line sizes plus the need to simulate
at multiple corners.
- SoC design data often explodes then collapses, such as with
regression analysis.
What makes big data into Big Data is the size of your search space. The
search space can grow big due to the sheer size of the raw data -- or due
to the structure and relations inside the data.
IC data is object data with complex relationships and would typically be
converted into a tabular form for Big-Data-like processing. So while your
stored data sets might have huge differences, by the time analysis is to be
done they are probably pretty similar.
---- ---- ---- ---- ---- ---- ----
VARIETY
Comparing SoC design data volume to other Big Data applications:
- Oil/Gas, Biomedical, etc.: 100's of Terabytes to 10's of Petabytes
- SOC/IC/IP design: 10's to 100's of Terabytes
SoC data volume is driven by: advanced process nodes, timing, 3D, layout,
power, characterization, modeling, synthesis, manufacturability, yield,
verification (simulation, regressions, physical verification...)
- Data volume is only getting bigger with smaller feature sizes,
due to nonlinear behavior at these nodes, as well as the physical
effects of decreasing line sizes plus the need to simulate
at multiple corners.
- SoC design data often explodes then collapses, such as with
regression analysis.
What makes big data into Big Data is the size of your search space. The
search space can grow big due to the sheer size of the raw data -- or due
to the structure and relations inside the data.
IC data is object data with complex relationships and would typically be
converted into a tabular form for Big-Data-like processing. So while your
stored data sets might have huge differences, by the time analysis is to be
done they are probably pretty similar.
---- ---- ---- ---- ---- ---- ----
VARIETY
 SoC design and verification data variety is more diverse than most Big Data
applications. The SoC data comes in a lot of different types and formats
spanning: C, RTL, GDSII, text files, binary files, schematics, IP properties,
bug notations, metadata, and temporal data.
Further, there are a lot of intermediate steps in SoC data; all the timing
runs on block M that failed, all the permutations on that PLL, all those
times the DRC run queue depth was 200. Much of this "throw away" SoC data
could actually provide tremendous insights. For example, all your "failed
run" throw away data could be analyzed to help find issues earlier in your
design cycle.
Also, designs and IP have a lifetime much larger than a single project.
---- ---- ---- ---- ---- ---- ----
VELOCITY
SoC design and verification data variety is more diverse than most Big Data
applications. The SoC data comes in a lot of different types and formats
spanning: C, RTL, GDSII, text files, binary files, schematics, IP properties,
bug notations, metadata, and temporal data.
Further, there are a lot of intermediate steps in SoC data; all the timing
runs on block M that failed, all the permutations on that PLL, all those
times the DRC run queue depth was 200. Much of this "throw away" SoC data
could actually provide tremendous insights. For example, all your "failed
run" throw away data could be analyzed to help find issues earlier in your
design cycle.
Also, designs and IP have a lifetime much larger than a single project.
---- ---- ---- ---- ---- ---- ----
VELOCITY
 Some Big Data uses involve large volumes of data streaming in real time. If
you look at all the searches being performed on Google or a full feed of all
of Twitter you get a high velocity Big Data stream.
In general, SoC design does not involve high velocity data because there is
very little real time data.
However, we have used parallel executions of Verilog/VHDL/SPICE simulations
for years. The large compute farms generating this simulation data could
actually deliver significant real time data if you wanted it.
---- ---- ---- ---- ---- ---- ----
COMPLEXITY
Some Big Data uses involve large volumes of data streaming in real time. If
you look at all the searches being performed on Google or a full feed of all
of Twitter you get a high velocity Big Data stream.
In general, SoC design does not involve high velocity data because there is
very little real time data.
However, we have used parallel executions of Verilog/VHDL/SPICE simulations
for years. The large compute farms generating this simulation data could
actually deliver significant real time data if you wanted it.
---- ---- ---- ---- ---- ---- ----
COMPLEXITY
 Chip design inherently has more complex relationships than other Big Data
applications. Much of its complexity comes from the different layers of
your design, but even more comes complexity from the relationships between
the elements that make up a device in it's many different forms -- i.e. the
C code, Verilog code, gates, transistors, wires, parasitics, etc.
Furthermore designs are no longer islands -- they have a long history of use
from 90 nm to 65 nm to 28 nm -- plus changes, modifications, and re-use.
Interlayer relationships explode the possible data space you must explore.
For example, correlating early bugs in your C++ models to Verilog RTL to
gates to GDSII is very hard to do for one chip -- let alone for a family of
derivative chips your group has designed over the past 10 years. This
expansion is not just additive; but more like taking a cross product.
Relationship knowledge not only indicates how to form your data space, but
also how to intelligently navigate it. This centralized view allows you to
find correlations and patterns that might otherwise be missed. For example,
finding out how certain Verilog coding styles cause your regressions to have
lower test coverage on certain physical parts of your chip. Or how certain
logic constructs increase your chip's dynamic power consumption.
It can be difficult to scale data mining to multiple dimensions, especially
when the relationships are complex and not explicitly defined. Two quick
examples:
Simple: How many customers buy product XX and product YY at the
same time?
Complex: How many times do I have two 3-input NAND gates feeding
into a 2-input NOR gate in my layout?
The "complex" example not only requires looking at the elements but also
looking at the connections between those elements. As you can see, it's a
large exploration space. The "simple" example is just a Venn intersection
of two data sets.
When you want to analyze data, you must understand all the rules by which
they were transformed. Most analytics have a temporal relationship, e.g.
how they evolve over time. You need to be able to look at the patterns to
mine from your project.
If you can't see the relationship - it's noise.
This goes beyond just looking at the physical structure of a circuit. From
a global view over time, there are relationships between file changes and
how they relate. For example, an engineer checks in a buggy RTL block. It
ripples downstream perturbing the design all the way through to Pentium PC's
having multiplication errors. Anything that helps to isolate data elements
is golden. That is, it's good to see how everything is inter-connected.
Even for your design's "state spaces", knowing an object was moved -- i.e.
is reused in many different forms in your design -- reduces the search space
for your analytics. Everything you know is an object with an attribute.
For example, you may have to may have to walk a hierarchy at the RTL level
and correlate it with physical GDSII structures. Expect to be taking slices
of data along design dimensions like: time, object relations, functional
relationships -- and then converting them to a (tabular) form where Big Data
analysis can be applied.
This strongly differs from just blindly looking over surface data. Without
knowing how your project data layers are interrelated, it takes extra time
and energy to derive relationships, to the point where the entire analytic
process can become impractical.
---- ---- ---- ---- ---- ---- ----
BIG DATA REQUIRES THE "RIGHT" DATA STRUCTURE
Our industry has been doing some "Big-Data"-like things for a long time.
We've had huge compute farms working on a single data set -- way before the
invention of "Big Data". But we've never captured ALL the data nor ever
attempted to analyze it for trends and patterns.
For systems, semiconductor, and IP companies, relevant data exists both
internal to the design data management system and external to it.
In fact, your DM system is the root and source of the vast majority of your
data. It is where all the interdependencies and bindings are held -- plus
where the temporal aspects are also captured. But it does not contain all
your log files, your run result files, and your detailed files.
For any analysis having a time domain, you need to maintain the history of
all state points. When you move through a design space, you need to be able
to see all the relationships -- and to also ensure that they are predictably
maintained.
As an example a design might be in a "done" state for several iterations as
issues are resolved. Being able to look over those iterations may be very
insightful, but it would be impossible if the only data being retained was
the final "done".
In the relatively unstructured file-name domain, you must identify the data
relationships before doing big data analysis. One approach this is to
search using common patterns, along with mapping techniques; this can be
very expensive from a processing and disc I/O standpoint.
Ensuring your data is structured in advance through an object model or
container model in your DM system will reduce later processing overhead
you'll need to find data relationships. An object model allows both
encapsulation of multiple data types internal to your DM system, along
with attachments for external data.
The object model should also support hierarchical relationships and
inheritance so that derived data can easily be traced back along its
generation path.
Objects can be compartmentalized for projects or IPs, such as "projects
taped out last year."
1. One object model approach is the repository name space in your
DM system can be decoupled from the file-system namespace. For
example, an object represented as "xchip/revA/block12/" in your
repository can be written to the disc as "foundry/ip_35/rel2".
Since the names are just virtual copies, your data mining is
able to focus on related and relevant object attributes rather
than on individual files and their naming:
"Give me a list of all GDSII objects generated
between January 15 and February 20."
2. A change-based DM system would then retain all of the implicit
configuration snapshots, such as:
"When the GDSII was modified on Feb 3, what
did the interrelated files look like?"
3. Once you have these relationships, you will want to bind them to
other information (such as derived data that is not necessarily
collected in the DM system.)
"Before I generated this GDSII, I had 12 sets
of SPICE run data on the server farm and here
is where I put it."
Big Data analytics for EDA require that you capture, store, and index data,
with time-based structures -- and are then later you are able to do search,
retrieval/export and analysis of data, across time/experience. Structured
metadata makes this possible.
---- ---- ---- ---- ---- ---- ----
COLLECT DATA NOW FOR BIG DATA ANALYTICS LATER
For design and verification teams, the keys to optimizing their development
processes are available within all that data generated. By gathering and
applying the appropriate analytics to their design and management data, you
can discover insights in their design processes. For example, code written
after 5:00 PM on Fridays has a very high error rate. With experience, this
sort of knowledge can be provided in real time with minimal impact on the
design teams themselves.
But you can't analyze data you don't have. If you want to apply Big Data
analytics to your SoC, IC and IP designs in the future -- you need to start
saving more of your design and verification data now.
By capturing multiple cycles of design data now, you will be able to later
find patterns to make better decisions. To get a critical mass of data, you
will need the complete historic and evolutionary data of several projects.
To ignore this is to effectively squander a future opportunity.
There are all sorts of "new" Big Data analytics coming out every few months.
Plan ahead now so you can use these new tools in the future.
- Dean Drako
IC Manage Campbell, CA
---- ---- ---- ---- ---- ---- ----
Related Articles
15 gotchas found in Design and IP data management tools (part I)
15 gotchas found in Design and IP data management tools (part II)
Dean Drako on IC Manage, Subversion, DesignSync, ClioSoft, CVS
Chip design inherently has more complex relationships than other Big Data
applications. Much of its complexity comes from the different layers of
your design, but even more comes complexity from the relationships between
the elements that make up a device in it's many different forms -- i.e. the
C code, Verilog code, gates, transistors, wires, parasitics, etc.
Furthermore designs are no longer islands -- they have a long history of use
from 90 nm to 65 nm to 28 nm -- plus changes, modifications, and re-use.
Interlayer relationships explode the possible data space you must explore.
For example, correlating early bugs in your C++ models to Verilog RTL to
gates to GDSII is very hard to do for one chip -- let alone for a family of
derivative chips your group has designed over the past 10 years. This
expansion is not just additive; but more like taking a cross product.
Relationship knowledge not only indicates how to form your data space, but
also how to intelligently navigate it. This centralized view allows you to
find correlations and patterns that might otherwise be missed. For example,
finding out how certain Verilog coding styles cause your regressions to have
lower test coverage on certain physical parts of your chip. Or how certain
logic constructs increase your chip's dynamic power consumption.
It can be difficult to scale data mining to multiple dimensions, especially
when the relationships are complex and not explicitly defined. Two quick
examples:
Simple: How many customers buy product XX and product YY at the
same time?
Complex: How many times do I have two 3-input NAND gates feeding
into a 2-input NOR gate in my layout?
The "complex" example not only requires looking at the elements but also
looking at the connections between those elements. As you can see, it's a
large exploration space. The "simple" example is just a Venn intersection
of two data sets.
When you want to analyze data, you must understand all the rules by which
they were transformed. Most analytics have a temporal relationship, e.g.
how they evolve over time. You need to be able to look at the patterns to
mine from your project.
If you can't see the relationship - it's noise.
This goes beyond just looking at the physical structure of a circuit. From
a global view over time, there are relationships between file changes and
how they relate. For example, an engineer checks in a buggy RTL block. It
ripples downstream perturbing the design all the way through to Pentium PC's
having multiplication errors. Anything that helps to isolate data elements
is golden. That is, it's good to see how everything is inter-connected.
Even for your design's "state spaces", knowing an object was moved -- i.e.
is reused in many different forms in your design -- reduces the search space
for your analytics. Everything you know is an object with an attribute.
For example, you may have to may have to walk a hierarchy at the RTL level
and correlate it with physical GDSII structures. Expect to be taking slices
of data along design dimensions like: time, object relations, functional
relationships -- and then converting them to a (tabular) form where Big Data
analysis can be applied.
This strongly differs from just blindly looking over surface data. Without
knowing how your project data layers are interrelated, it takes extra time
and energy to derive relationships, to the point where the entire analytic
process can become impractical.
---- ---- ---- ---- ---- ---- ----
BIG DATA REQUIRES THE "RIGHT" DATA STRUCTURE
Our industry has been doing some "Big-Data"-like things for a long time.
We've had huge compute farms working on a single data set -- way before the
invention of "Big Data". But we've never captured ALL the data nor ever
attempted to analyze it for trends and patterns.
For systems, semiconductor, and IP companies, relevant data exists both
internal to the design data management system and external to it.
In fact, your DM system is the root and source of the vast majority of your
data. It is where all the interdependencies and bindings are held -- plus
where the temporal aspects are also captured. But it does not contain all
your log files, your run result files, and your detailed files.
For any analysis having a time domain, you need to maintain the history of
all state points. When you move through a design space, you need to be able
to see all the relationships -- and to also ensure that they are predictably
maintained.
As an example a design might be in a "done" state for several iterations as
issues are resolved. Being able to look over those iterations may be very
insightful, but it would be impossible if the only data being retained was
the final "done".
In the relatively unstructured file-name domain, you must identify the data
relationships before doing big data analysis. One approach this is to
search using common patterns, along with mapping techniques; this can be
very expensive from a processing and disc I/O standpoint.
Ensuring your data is structured in advance through an object model or
container model in your DM system will reduce later processing overhead
you'll need to find data relationships. An object model allows both
encapsulation of multiple data types internal to your DM system, along
with attachments for external data.
The object model should also support hierarchical relationships and
inheritance so that derived data can easily be traced back along its
generation path.
Objects can be compartmentalized for projects or IPs, such as "projects
taped out last year."
1. One object model approach is the repository name space in your
DM system can be decoupled from the file-system namespace. For
example, an object represented as "xchip/revA/block12/" in your
repository can be written to the disc as "foundry/ip_35/rel2".
Since the names are just virtual copies, your data mining is
able to focus on related and relevant object attributes rather
than on individual files and their naming:
"Give me a list of all GDSII objects generated
between January 15 and February 20."
2. A change-based DM system would then retain all of the implicit
configuration snapshots, such as:
"When the GDSII was modified on Feb 3, what
did the interrelated files look like?"
3. Once you have these relationships, you will want to bind them to
other information (such as derived data that is not necessarily
collected in the DM system.)
"Before I generated this GDSII, I had 12 sets
of SPICE run data on the server farm and here
is where I put it."
Big Data analytics for EDA require that you capture, store, and index data,
with time-based structures -- and are then later you are able to do search,
retrieval/export and analysis of data, across time/experience. Structured
metadata makes this possible.
---- ---- ---- ---- ---- ---- ----
COLLECT DATA NOW FOR BIG DATA ANALYTICS LATER
For design and verification teams, the keys to optimizing their development
processes are available within all that data generated. By gathering and
applying the appropriate analytics to their design and management data, you
can discover insights in their design processes. For example, code written
after 5:00 PM on Fridays has a very high error rate. With experience, this
sort of knowledge can be provided in real time with minimal impact on the
design teams themselves.
But you can't analyze data you don't have. If you want to apply Big Data
analytics to your SoC, IC and IP designs in the future -- you need to start
saving more of your design and verification data now.
By capturing multiple cycles of design data now, you will be able to later
find patterns to make better decisions. To get a critical mass of data, you
will need the complete historic and evolutionary data of several projects.
To ignore this is to effectively squander a future opportunity.
There are all sorts of "new" Big Data analytics coming out every few months.
Plan ahead now so you can use these new tools in the future.
- Dean Drako
IC Manage Campbell, CA
---- ---- ---- ---- ---- ---- ----
Related Articles
15 gotchas found in Design and IP data management tools (part I)
15 gotchas found in Design and IP data management tools (part II)
Dean Drako on IC Manage, Subversion, DesignSync, ClioSoft, CVS
Join
Index
Next->Item
|
|









