( ESNUG 511 Item 2 ) -------------------------------------------- [10/09/12]
Subject: Common definitions of On-Chip Communication Network (OCCN) terms
From: [ Jim Hogan of Vista Ventures LLC ]
Hi, John,
Here's the list of commonly used network-on-chip (NoC) terms:
- On-Chip Communication Network (On-Chip Network)
- Bus matrix
- Crossbar
- Network-on-Chip (NoC)
- System IP
- Virtual Channels or Multi-Threads
- Quality of Service
- Head-of-Line Blocking
- Non-blocking flow
- Cache Coherency
Hopefully a chip designer can read these definitions in this order to get a
rough idea of how NoC's work and are discussed.
- Jim Hogan
Vista Ventures, LLC Los Gatos, CA
---- ---- ---- ---- ---- ---- ----
On-Chip Communication Network (OCCN)
An On-Chip Communication Network, also known as an On-Chip Network (OCN), is
the entire interconnect fabric for an SoC.
 On-Chip Communications Network
Source: Sonics Inc., 2012
It includes elements necessary for flexible topologies like NoCs, Crossbars,
Peripheral IP, and multi-layer Bus Matrices. For example, the OCCN in this
design above consists of 1 Network-on-Chip (NoC) plus 2 peripheral networks.
---- ---- ---- ---- ---- ---- ----
Bus Matrix
A traditional bus matrix is a basic interconnect, usually connecting 1 to 2
cores (CPU, DMA, GPU's) to other IP elements, with perhaps 4-5 connections.
On-Chip Communications Network
Source: Sonics Inc., 2012
It includes elements necessary for flexible topologies like NoCs, Crossbars,
Peripheral IP, and multi-layer Bus Matrices. For example, the OCCN in this
design above consists of 1 Network-on-Chip (NoC) plus 2 peripheral networks.
---- ---- ---- ---- ---- ---- ----
Bus Matrix
A traditional bus matrix is a basic interconnect, usually connecting 1 to 2
cores (CPU, DMA, GPU's) to other IP elements, with perhaps 4-5 connections.
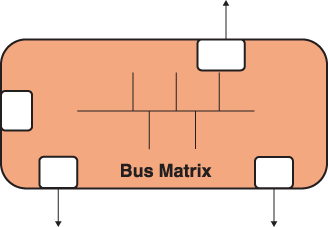 With a bus matrix, there's usually one level of communication between master
and slave. Bus matrix implementation is done using simple multiplexers and
splitters to connect the cores together. The designer assembles the bus
matrix from a library of functional blocks. ĀBus matrix IP is typically
designed in-house or purchased from Synopsys or ARM. Scaling is done with
multiple levels of bus matrixes -- layers of processing elements, branches
of peripherals, connected by one bus matrix.
---- ---- ---- ---- ---- ---- ----
Crossbar
A crossbar is a configurable network interconnect that provides parallel
access connecting multiple cores, with socket support for standard interface
protocols, such as AMBA, OCP, PIF or proprietary. ĀBecause all the data and
addresses go out to all IP blocks at once, crossbars provide low latency
connectivity, but its layout is more challenging.
With a bus matrix, there's usually one level of communication between master
and slave. Bus matrix implementation is done using simple multiplexers and
splitters to connect the cores together. The designer assembles the bus
matrix from a library of functional blocks. ĀBus matrix IP is typically
designed in-house or purchased from Synopsys or ARM. Scaling is done with
multiple levels of bus matrixes -- layers of processing elements, branches
of peripherals, connected by one bus matrix.
---- ---- ---- ---- ---- ---- ----
Crossbar
A crossbar is a configurable network interconnect that provides parallel
access connecting multiple cores, with socket support for standard interface
protocols, such as AMBA, OCP, PIF or proprietary. ĀBecause all the data and
addresses go out to all IP blocks at once, crossbars provide low latency
connectivity, but its layout is more challenging.
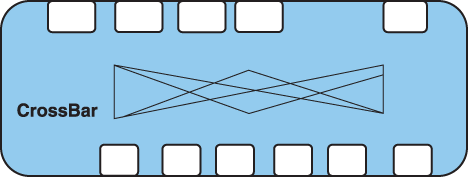 There are many different implementations of crossbars. For example, some
offer a crossbar where all paths between IP cores are connected at fixed
widths, i.e. a fully populated matrix. This approach relies on the EDA
tools to eliminate unused paths.
Another crossbar implementation constructs paths only as required, rather
than relying on EDA tools to delete the unused paths. SoC's with mixed
cores don't require all cores to talk to all other cores. Processor
cores -- like CPU's, GPU's, graphics uP's -- all funnel traffic in/out of a
shared memory.
Differing bus widths help provide your required bandwidth. Crossbars with
high performance and low latency, often are optimum for reusable subsystems
like audio & video designs.
---- ---- ---- ---- ---- ---- ----
Network-on-Chip (NoC)
A Network-on-Chip is a configurable network interconnect that packetizes
address/data for multicore SoCs. The advantages of using a NoC includes
high scalability and supporting an ever increasing number of IP cores.
A packetized network provides the high-performance needed by advanced
CPU/GPU cores. By using routers as the fundamental switching elements,
optimized topologies can be developed for maximum data bandwidth. NoC's
support standard protocols like as AMBA, OCP, PIF or proprietary IP.
There are many different implementations of crossbars. For example, some
offer a crossbar where all paths between IP cores are connected at fixed
widths, i.e. a fully populated matrix. This approach relies on the EDA
tools to eliminate unused paths.
Another crossbar implementation constructs paths only as required, rather
than relying on EDA tools to delete the unused paths. SoC's with mixed
cores don't require all cores to talk to all other cores. Processor
cores -- like CPU's, GPU's, graphics uP's -- all funnel traffic in/out of a
shared memory.
Differing bus widths help provide your required bandwidth. Crossbars with
high performance and low latency, often are optimum for reusable subsystems
like audio & video designs.
---- ---- ---- ---- ---- ---- ----
Network-on-Chip (NoC)
A Network-on-Chip is a configurable network interconnect that packetizes
address/data for multicore SoCs. The advantages of using a NoC includes
high scalability and supporting an ever increasing number of IP cores.
A packetized network provides the high-performance needed by advanced
CPU/GPU cores. By using routers as the fundamental switching elements,
optimized topologies can be developed for maximum data bandwidth. NoC's
support standard protocols like as AMBA, OCP, PIF or proprietary IP.
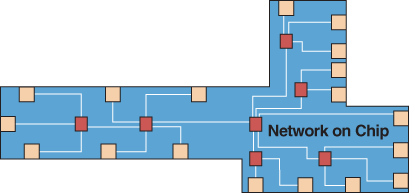 Its topology can be tuned for optimization of latency, speed, and power
tradeoffs. Because NoCs use a packetized approach, they are typically
higher frequency, and higher latency than a crossbar matrix.
Because NoC's have fewer wires, there can be less routing congestion.
---- ---- ---- ---- ---- ---- ----
System IP
System IP typically includes:
- On-Chip Network IP
- Memory subsystem IP
-ĀPower management IP
- Security IP
-ĀPerformance IP & Analysis
-ĀTest configuration IP
-ĀVerification IP
System IP is the technology and tools used to architect and test SoCs.
This includes 1.) integrating IP cores, 2.) modeling system performance,
power, and 3.) verification.
---- ---- ---- ---- ---- ---- ----
Virtual Channels or Multi-Threads
Virtual Channels (also known as Multi-Threads) use one physical connection
while supporting multiple virtual connections.
Its topology can be tuned for optimization of latency, speed, and power
tradeoffs. Because NoCs use a packetized approach, they are typically
higher frequency, and higher latency than a crossbar matrix.
Because NoC's have fewer wires, there can be less routing congestion.
---- ---- ---- ---- ---- ---- ----
System IP
System IP typically includes:
- On-Chip Network IP
- Memory subsystem IP
-ĀPower management IP
- Security IP
-ĀPerformance IP & Analysis
-ĀTest configuration IP
-ĀVerification IP
System IP is the technology and tools used to architect and test SoCs.
This includes 1.) integrating IP cores, 2.) modeling system performance,
power, and 3.) verification.
---- ---- ---- ---- ---- ---- ----
Virtual Channels or Multi-Threads
Virtual Channels (also known as Multi-Threads) use one physical connection
while supporting multiple virtual connections.
 Multi-Threading (or Virtual Channels) let 2 or 3 (or up to 16) CPU/GPU's use
one physical bus to access the external DRAM by time-division-MUXing all of
the 2 or 3 (or up to 16) CPU/GPU's outgoing transactions. This drastically
reduces CPU/GPU latency for the price of reduced bus bandwidth. (Since most
current designs have excess bus bandwith, it's no big thing to trade some
of it for better latency.)
Now one physical link appears as multiple logical links. Virtual Channels
increase the network efficiency without increasing the number of parallel
wires -- allowing multiple concurrent operations on the on-chip network.
An entire page on Virtual Channels is here.
---- ---- ---- ---- ---- ---- ----
Quality-of-Service (QoS)
Quality of Service is a method to provide data flow prioritization through
the network. Well defined QoS will result in a performance improvement by
allowing guaranteed bandwidth for critical network traffic.
Multi-Threading (or Virtual Channels) let 2 or 3 (or up to 16) CPU/GPU's use
one physical bus to access the external DRAM by time-division-MUXing all of
the 2 or 3 (or up to 16) CPU/GPU's outgoing transactions. This drastically
reduces CPU/GPU latency for the price of reduced bus bandwidth. (Since most
current designs have excess bus bandwith, it's no big thing to trade some
of it for better latency.)
Now one physical link appears as multiple logical links. Virtual Channels
increase the network efficiency without increasing the number of parallel
wires -- allowing multiple concurrent operations on the on-chip network.
An entire page on Virtual Channels is here.
---- ---- ---- ---- ---- ---- ----
Quality-of-Service (QoS)
Quality of Service is a method to provide data flow prioritization through
the network. Well defined QoS will result in a performance improvement by
allowing guaranteed bandwidth for critical network traffic.
  For example, you play Angry Birds on your iPhone. You get a call. Good
QoS means your iPhone swaps from being a video game console and into a
working telephone in a matter of milliseconds -- so fast the user can't
detect the change. Conversely, a bad QoS would be your iPhone takes
40 seconds to transition from Angry Birds to being a working phone.
---- ---- ---- ---- ---- ---- ----
Head-of-Line Blocking
Head of Line blocking is when a high priority master such as a CPU or GPU is
denied access because of low priority data behavior.
---- ---- ---- ---- ---- ---- ----
Non-Blocking Flow
A non-blocking flow is an architecture that eliminates a high priority
master such as a CPU or GPU being denied access because of a low priority
data behavior.
---- ---- ---- ---- ---- ---- ----
Cache Coherency
Cache Coherency is a scheme that keeps all levels of cached data up-to-date.
Various levels of cache memory are deployed throughout an SoC for faster
recall of important data. Cache memory locally stores the most recently
used instructions and data. It speeds up software loops and indexed data
array operations because everything is local. No waits for anything!
int total_pay = 0;
int day = 1;
while (day < 8) {
total_pay = total_pay + pay[day];
day++;
}
example software loop and indexed data to calculate one week's pay
In addition, loops and indexed data are the most common SW operations. The
reduced latency of on-chip cache memory is usually under 10 processor clock
cycles as compared to on-the-order-of 100 clock cycles (or more at higher
frequencies) to access an external DRAM. Caches improve Quality-of-Service.
Since multiple CPU/GPU/DSP's can be operating at the same time on the same
data at the same address in a chip's memory -- the on-chip network must
ensure Cache Coherency -- i.e. all cached data on all the CPU/GPU/DSP's are
up-to-date with each other.
---- ---- ---- ---- ---- ---- ----
Related Articles
Hogan outlines key market drivers for Network-on-Chip (NoC) IP
Exploring a designer's Make-or-Buy decision for On-Chip Networks
Metrics checklist for selecting commercial Network-on-Chip (NoC)
A detailed discussion of On-Chip Networks with Virtual Channels
Hogan compares Sonics SGN vs. Arteris Flex NOC vs. ARM NIC 400
For example, you play Angry Birds on your iPhone. You get a call. Good
QoS means your iPhone swaps from being a video game console and into a
working telephone in a matter of milliseconds -- so fast the user can't
detect the change. Conversely, a bad QoS would be your iPhone takes
40 seconds to transition from Angry Birds to being a working phone.
---- ---- ---- ---- ---- ---- ----
Head-of-Line Blocking
Head of Line blocking is when a high priority master such as a CPU or GPU is
denied access because of low priority data behavior.
---- ---- ---- ---- ---- ---- ----
Non-Blocking Flow
A non-blocking flow is an architecture that eliminates a high priority
master such as a CPU or GPU being denied access because of a low priority
data behavior.
---- ---- ---- ---- ---- ---- ----
Cache Coherency
Cache Coherency is a scheme that keeps all levels of cached data up-to-date.
Various levels of cache memory are deployed throughout an SoC for faster
recall of important data. Cache memory locally stores the most recently
used instructions and data. It speeds up software loops and indexed data
array operations because everything is local. No waits for anything!
int total_pay = 0;
int day = 1;
while (day < 8) {
total_pay = total_pay + pay[day];
day++;
}
example software loop and indexed data to calculate one week's pay
In addition, loops and indexed data are the most common SW operations. The
reduced latency of on-chip cache memory is usually under 10 processor clock
cycles as compared to on-the-order-of 100 clock cycles (or more at higher
frequencies) to access an external DRAM. Caches improve Quality-of-Service.
Since multiple CPU/GPU/DSP's can be operating at the same time on the same
data at the same address in a chip's memory -- the on-chip network must
ensure Cache Coherency -- i.e. all cached data on all the CPU/GPU/DSP's are
up-to-date with each other.
---- ---- ---- ---- ---- ---- ----
Related Articles
Hogan outlines key market drivers for Network-on-Chip (NoC) IP
Exploring a designer's Make-or-Buy decision for On-Chip Networks
Metrics checklist for selecting commercial Network-on-Chip (NoC)
A detailed discussion of On-Chip Networks with Virtual Channels
Hogan compares Sonics SGN vs. Arteris Flex NOC vs. ARM NIC 400
Join
Index
Next->Item
|
|





